
.%*. .-.
.%@@@+. .--=%@@@-
=@@@@@@- :--+@@@@@@@@@*
*@%@@@@@%: :--=#@@@@@@@@@@@@#@@+
@@::%@@@@@@-: :::-=%@@@@@@@@@@@@@@%#*- :@*
.@@ =@@@@@@@@@+-:::::::-=*@@@@@@@@@@@@@@@@@@@%##- @@:
#@# +%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@%%#*: -@@
#@- *%@@@@@@@@@@@@@@@@@%%%#= %@=
@@: -=+++== .. @@:
@@ . -@@@ +@@
#@% =@@@@- +@@@@# *+ %@#
#@- -@@@@@@@. +@@@@@% .%@@@@= @@:
@@: +@@@@@@@@@ +@+ +@@@ %@@@@@@@@@ -@@
@@ *@%@* :@@@ *@+ -@@@ %@@@@@@@@@@@# @@@
#@% %@ @% %@@ *@* .@@@ =@@@*@@ :@@@@ @@:
%@:## *@+ :@@ :@@ @@@ %@@: @# .@@@ .@@
@@:. @@: .@@ @@ @@@ %@: @@ @@% @@%
@@ -@@. =@@ @@. @@@ %@. #@- @@# @@.
%@% +@@. @@. %@- @@@ #@ @@. :@@ -@@
%@: +@@+ .@% #@= @@@.@ *@@ +@+ @@*
@@: +@@%. .%% *@+ @@@ %@@ -@# @@
@@ :@@@@@@% :@@ @@% %@@ @# *@@
%@@ #@@@@* @@ @@% %@@. %@. @@:
@@: ===: @@. @@% %@@: =@%. .@@
@@. #@= @@% %@@%+%@#. @@%
@@ +@* @@# -@@@@@* .@@
%@@ :@@ @@# %@@#: =@@
@@: .@@ @@# : @@=
@@. @@. @@# :@@
@@ #@= @@% %@%
#@@ +@+ #@% .@@
@@: =@# +@% =@%
@@ :@% -@@ @@+
@@ .@@ -@: -@@
-@@ @% .: *@#
@@* # @@.
@@ =@@
.@@ @@*
.@@ .@@
*@@ =@#
@@* @@*
@@ -@@
.@@ +@*
.@@ @@-
-@@ =@@
%@% #@*
@@ @@:
@@ +@@
.@@ %@+
:@% @@.
:@% *@%
-@. %@=
%@ @@.
@@ *@%
@@ %@=
@% @@:
:@% +@@
:@* =+- #@+
:@: .%@@@. @@-
-@ =@@@@@# :@@
=@ *@#.=@@% #@%
*@ #@- -@@% %@-
@@ #@: :@@% @@:
@@ #% .@@% .#@@* -@@
@% #% .@@% +@@@@@- %@%
@# %@ :@@% .@@@@@@@@ %@:
@# %@ :@@% +@@% .@@@@ @@:
@# %@ :@@% #@@: :@@@ -@@
@# @@. .@@@ .@@% .@@@= %@%
@# @@. .@@@: %@@- @@@% %@:
@# @@ @@@@ %@@@ *@@@ @@:
@# .@@ @@@@@@@@@@= :@@@ @@
* @@@ :@@@@@@@@. :@@@ *@@
.@@@@@% -@@@@@. .@@@ @@=
@@@@@: .. @@@ @@.
-@%: @@@ @@.
@@@ @@
-@@ =@@
.@@ @@+
.@@:@@.
@@#@-
@@@.
+@-
-
mediocregopher's lil web corner
- Discussing the nature of program structure, the problems presented by complex structures, and a pattern that helps in solving those problems.
This post is focused on a concept I call “program structure,” which I will try to shed some light on before discussing complex program structures. I will then discuss why complex structures can be problematic to deal with, and will finally discuss a pattern for dealing with those problems.
My background is as a backend engineer working on large projects that have had many moving parts; most had multiple programs interacting with each other, used many different databases in various contexts, and faced large amounts of load from millions of users. Most of this post will be framed from my perspective, and will present problems in the way I have experienced them. I believe, however, that the concepts and problems I discuss here are applicable to many other domains, and I hope those with a foot in both backend systems and a second domain can help to translate the ideas between the two.
Also note that I will be using Go as my example language, but none of the concepts discussed here are specific to Go. To that end, I’ve decided to favor readable code over “correct” code, and so have elided things that most gophers hold near-and-dear, such as error checking and proper documentation, in order to make the code as accessible as possible to non-gophers as well. As with before, I trust that someone with a foot in Go and another language can help me translate between the two.
In this section I will discuss the difference between directory and program structure, show how global state is antithetical to compartmentalization (and therefore good program structure), and finally discuss a more effective way to think about program structure.
For a long time, I thought about program structure in terms of the hierarchy present in the filesystem. In my mind, a program’s structure looked like this:
// The directory structure of a project called gobdns.
src/
config/
dns/
http/
ips/
persist/
repl/
snapshot/
main.go
What I grew to learn was that this conflation of “program structure” with “directory structure” is ultimately unhelpful. While it can’t be denied that every program has a directory structure (and if not, it ought to), this does not mean that the way the program looks in a filesystem in any way corresponds to how it looks in our mind’s eye.
The most notable way to show this is to consider a library package. Here is the structure of a simple web-app which uses redis (my favorite database) as a backend:
src/
redis/
http/
main.go
If I were to ask you, based on that directory structure, what the program does in the most abstract terms, you might say something like: “The program establishes an http server that listens for requests. It also establishes a connection to the redis server. The program then interacts with redis in different ways based on the http requests that are received on the server.”
And that would be a good guess. Here’s a diagram that depicts the program
structure, wherein the root node, main.go, takes in requests from http and
processes them using redis.
This is certainly a viable guess for how a program with that directory
structure operates, but consider another answer: “A component of the program
called server establishes an http server that listens for requests. server
also establishes a connection to a redis server. server then interacts with
that redis connection in different ways based on the http requests that are
received on the http server. Additionally, server tracks statistics about
these interactions and makes them available to other components. The root
component of the program establishes a connection to a second redis server, and
stores those statistics in that redis server.” Here’s another diagram to depict
that program.
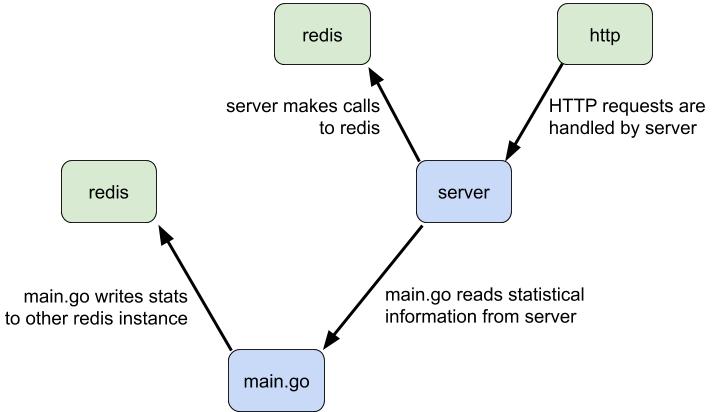
The directory structure could apply to either description; redis is just a
library which allows for interaction with a redis server, but it doesn’t
specify which or how many servers. However, those are extremely important
factors that are definitely reflected in our concept of the program’s
structure, and not in the directory structure. What the directory structure
reflects are the different kinds of components available to use, but it does
not reflect how a program will use those components.
The directory-centric view of structure often leads to the use of global
singletons to manage access to external resources like RPC servers and
databases. In examples 1 and 2 the redis library might contain code which
looks something like this:
// A mapping of connection names to redis connections.
var globalConns = map[string]*RedisConn{}
func Get(name string) *RedisConn {
if globalConns[name] == nil {
globalConns[name] = makeRedisConnection(name)
}
return globalConns[name]
}
Even though this pattern would work, it breaks with our conception of the
program structure in more complex cases like example 2. Rather than the redis
component being owned by the server component, which actually uses it, it
would be practically owned by all components, since all are able to use it.
Compartmentalization has been broken, and can only be held together through
sheer human discipline.
This is the problem with all global state. It is shareable among all components of a program, and so is accountable to none of them. One must look at an entire codebase to understand how a globally held component is used, which might not even be possible for a large codebase. Therefore, the maintainers of these shared components rely entirely on the discipline of their fellow coders when making changes, usually discovering where that discipline broke down once the changes have been pushed live.
Global state also makes it easier for disparate programs/components to share datastores for completely unrelated tasks. In example 2, rather than creating a new redis instance for the root component’s statistics storage, the coder might have instead said, “well, there’s already a redis instance available, I’ll just use that.” And so, compartmentalization would have been broken further. Perhaps the two instances could be coalesced into the same instance for the sake of resource efficiency, but that decision would be better made at runtime via the configuration of the program, rather than being hardcoded into the code.
From the perspective of team management, global state-based patterns do nothing
except slow teams down. The person/team responsible for maintaining the central
library in which shared components live (redis, in the above examples)
becomes the bottleneck for creating new instances for new components, which
will further lead to re-using existing instances rather than creating new ones,
further breaking compartmentalization. Additionally the person/team responsible
for the central library, rather than the team using it, often finds themselves
as the maintainers of the shared resource.
So what does proper program structure look like? In my mind the structure of a program is a hierarchy of components, or, in other words, a tree. The leaf nodes of the tree are almost always IO related components, e.g., database connections, RPC server frameworks or clients, message queue consumers, etc. The non-leaf nodes will generally be components that bring together the functionalities of their children in some useful way, though they may also have some IO functionality of their own.
Let's look at an even more complex structure, still only using the redis and
http component types:
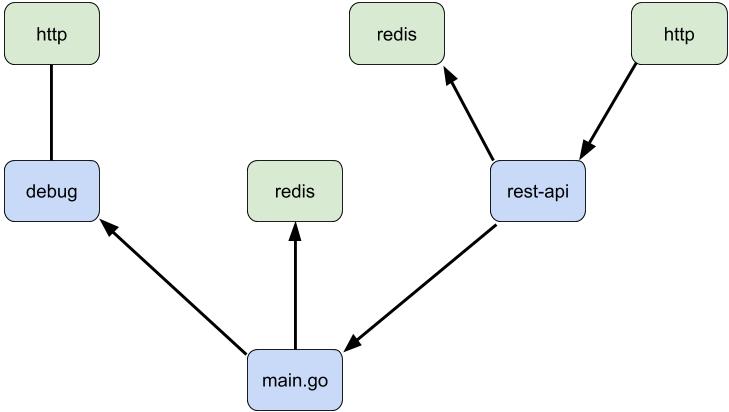
This component structure contains the addition of the debug component.
Clearly the http and redis components are reusable in different contexts,
but for this example the debug endpoint is as well. It creates a separate
http server that can be queried to perform runtime debugging of the program,
and can be tacked onto virtually any program. The rest-api component is
specific to this program and is therefore not reusable. Let’s dive into it a
bit to see how it might be implemented:
// RestAPI is very much not thread-safe, hopefully it doesn't have to handle
// more than one request at once.
type RestAPI struct {
redisConn *redis.RedisConn
httpSrv *http.Server
// Statistics exported for other components to see
RequestCount int
FooRequestCount int
BarRequestCount int
}
func NewRestAPI() *RestAPI {
r := new(RestAPI)
r.redisConn := redis.NewConn("127.0.0.1:6379")
// mux will route requests to different handlers based on their URL path.
mux := http.NewServeMux()
mux.HandleFunc("/foo", r.fooHandler)
mux.HandleFunc("/bar", r.barHandler)
r.httpSrv := http.NewServer(mux)
// Listen for requests and serve them in the background.
go r.httpSrv.Listen(":8000")
return r
}
func (r *RestAPI) fooHandler(rw http.ResponseWriter, r *http.Request) {
r.redisConn.Command("INCR", "fooKey")
r.RequestCount++
r.FooRequestCount++
}
func (r *RestAPI) barHandler(rw http.ResponseWriter, r *http.Request) {
r.redisConn.Command("INCR", "barKey")
r.RequestCount++
r.BarRequestCount++
}
In that snippet rest-api coalesced http and redis into a simple REST-like
api using pre-made library components. main.go, the root component, does much
the same:
func main() {
// Create debug server and start listening in the background
debugSrv := debug.NewServer()
// Set up the RestAPI, this will automatically start listening
restAPI := NewRestAPI()
// Create another redis connection and use it to store statistics
statsRedisConn := redis.NewConn("127.0.0.1:6380")
for {
time.Sleep(1 * time.Second)
statsRedisConn.Command("SET", "numReqs", restAPI.RequestCount)
statsRedisConn.Command("SET", "numFooReqs", restAPI.FooRequestCount)
statsRedisConn.Command("SET", "numBarReqs", restAPI.BarRequestCount)
}
}
One thing that is clearly missing in this program is proper configuration,
whether from command-line or environment variables, etc. As it stands, all
configuration parameters, such as the redis addresses and http listen
addresses, are hardcoded. Proper configuration actually ends up being somewhat
difficult, as the ideal case would be for each component to set up its own
configuration variables without its parent needing to be aware. For example,
redis could set up addr and pool-size parameters. The problem is that there
are two redis components in the program, and their parameters would therefore
conflict with each other. An elegant solution to this problem is discussed in
the next section.
The key to the configuration problem is to recognize that, even if there are
two of the same component in a program, they can’t occupy the same place in the
program’s structure. In the above example, there are two http components: one
under rest-api and the other under debug. Because the structure is
represented as a tree of components, the “path” of any node in the tree
uniquely represents it in the structure. For example, the two http components
in the previous example have these paths:
root -> rest-api -> http
root -> debug -> http
If each component were to know its place in the component tree, then it would
easily be able to ensure that its configuration and initialization didn’t
conflict with other components of the same type. If the http component sets
up a command-line parameter to know what address to listen on, the two http
components in that program would set up:
--rest-api-listen-addr
--debug-listen-addr
So how can we enable each component to know its path in the component structure?
To answer this, we’ll have to take a detour through a type, called Component.
The Component type is a made-up type (though you’ll be able to find an
implementation of it at the end of this post). It has a single primary purpose,
and that is to convey the program’s structure to new components.
To see how this is done, let's look at a couple of Component's methods:
// Package mcmp
// New returns a new Component which has no parents or children. It is therefore
// the root component of a component hierarchy.
func New() *Component
// Child returns a new child of the called upon Component.
func (*Component) Child(name string) *Component
// Path returns the Component's path in the component hierarchy. It will return
// an empty slice if the Component is the root component.
func (*Component) Path() []string
Child is used to create a new Component, corresponding to a new child node
in the component structure, and Path is used retrieve the path of any
Component within that structure. For the sake of keeping the examples simple,
let’s pretend these functions have been implemented in a package called mcmp.
Here’s an example of how Component might be used in the redis component’s
code:
// Package redis
func NewConn(cmp *mcmp.Component, defaultAddr string) *RedisConn {
cmp = cmp.Child("redis")
paramPrefix := strings.Join(cmp.Path(), "-")
addrParam := flag.String(paramPrefix+"-addr", defaultAddr, "Address of redis instance to connect to")
// finish setup
return redisConn
}
In our above example, the two redis components' parameters would be:
// This first parameter is for the stats redis, whose parent is the root and
// therefore doesn't have a prefix. Perhaps stats should be broken into its own
// component in order to fix this.
--redis-addr
--rest-api-redis-addr
Component definitely makes it easier to instantiate multiple redis components
in our program, since it allows them to know their place in the component
structure.
Having to construct the prefix for the parameters ourselves is pretty annoying,
so let’s introduce a new package, mcfg, which acts like flag but is aware
of Component. Then redis.NewConn is reduced to:
// Package redis
func NewConn(cmp *mcmp.Component, defaultAddr string) *RedisConn {
cmp = cmp.Child("redis")
addrParam := mcfg.String(cmp, "addr", defaultAddr, "Address of redis instance to connect to")
// finish setup
return redisConn
}
Easy-peasy.
Sharp-eyed gophers will notice that there is a key piece missing: When is
flag.Parse, or its mcfg counterpart, called? When does addrParam actually
get populated? It can’t happen inside redis.NewConn because there might be
other components after redis.NewConn that want to set up parameters. To
illustrate the problem, let’s look at a simple program that wants to set up two
redis components:
func main() {
// Create the root Component, an empty Component.
cmp := mcmp.New()
// Create the Components for two sub-components, foo and bar.
cmpFoo := cmp.Child("foo")
cmpBar := cmp.Child("bar")
// Now we want to try to create a redis sub-component for each component.
// This will set up the parameter "--foo-redis-addr", but bar hasn't had a
// chance to set up its corresponding parameter, so the command-line can't
// be parsed yet.
fooRedis := redis.NewConn(cmpFoo, "127.0.0.1:6379")
// This will set up the parameter "--bar-redis-addr", but, as mentioned
// before, redis.NewConn can't parse command-line.
barRedis := redis.NewConn(cmpBar, "127.0.0.1:6379")
// It is only after all components have been instantiated that the
// command-line arguments can be parsed
mcfg.Parse()
}
While this solves our argument parsing problem, fooRedis and barRedis are not
usable yet because the actual connections have not been made. This is a classic
chicken and the egg problem. The func redis.NewConn needs to make a connection
which it cannot do until after mcfg.Parse is called, but mcfg.Parse cannot
be called until after redis.NewConn has returned. We will solve this problem
in the next section.
Let’s break down redis.NewConn into two phases: instantiation and
initialization. Instantiation refers to creating the component on the component
structure and having it declare what it needs in order to initialize (e.g.,
configuration parameters). During instantiation, nothing external to the
program is performed; no IO, no reading of the command-line, no logging, etc.
All that’s happened is that the empty template of a redis component has been
created.
Initialization is the phase during which the template is filled in. Configuration parameters are read, startup actions like the creation of database connections are performed, and logging is output for informational and debugging purposes.
The key to making effective use of this dichotomy is to allow all components to instantiate themselves before they initialize themselves. By doing this we can ensure, for example, that all components have had the chance to declare their configuration parameters before configuration parsing is done.
So let’s modify redis.NewConn so that it follows this dichotomy. It makes
sense to leave instantiation-related code where it is, but we need a mechanism
by which we can declare initialization code before actually calling it. For
this, I will introduce the idea of a “hook.”
In order to support hooks, however, Component will need to be augmented with
a few new methods. Right now, it can only carry with it information about the
component structure, but here we will add the ability to carry arbitrary
key/value information as well:
// Package mcmp
// SetValue sets the given key to the given value on the Component, overwriting
// any previous value for that key.
func (*Component) SetValue(key, value interface{})
// Value returns the value which has been set for the given key, or nil if the
// key was never set.
func (*Component) Value(key interface{}) interface{}
// Children returns the Component's children in the order they were created.
func (*Component) Children() []*Component
The final method allows us to, starting at the root Component, traverse the
component structure and interact with each Component’s key/value store. This
will be useful for implementing hooks.
A hook is simply a function that will run later. We will declare a new package,
calling it mrun, and say that it has two new functions:
// Package mrun
// InitHook registers the given hook to the given Component.
func InitHook(cmp *mcmp.Component, hook func())
// Init runs all hooks registered using InitHook. Hooks are run in the order
// they were registered.
func Init(cmp *mcmp.Component)
With these two functions, we are able to defer the initialization phase of
startup by using the same Components we were passing around for the purpose
of denoting component structure.
Now, with these few extra pieces of functionality in place, let’s reconsider the most recent example, and make a program that creates two redis components which exist independently of each other:
// Package redis
// NOTE that NewConn has been renamed to InstConn, to reflect that the returned
// *RedisConn is merely instantiated, not initialized.
func InstConn(cmp *mcmp.Component, defaultAddr string) *RedisConn {
cmp = cmp.Child("redis")
// we instantiate an empty RedisConn instance and parameters for it. Neither
// has been initialized yet. They will remain empty until initialization has
// occurred.
redisConn := new(RedisConn)
addrParam := mcfg.String(cmp, "addr", defaultAddr, "Address of redis instance to connect to")
mrun.InitHook(cmp, func() {
// This hook will run after parameter initialization has happened, and
// so addrParam will be usable. Once this hook as run, redisConn will be
// usable as well.
*redisConn = makeRedisConnection(*addrParam)
})
// Now that cmp has had configuration parameters and intialization hooks
// set into it, return the empty redisConn instance back to the parent.
return redisConn
}
// Package main
func main() {
// Create the root Component, an empty Component.
cmp := mcmp.New()
// Create the Components for two sub-components, foo and bar.
cmpFoo := cmp.Child("foo")
cmpBar := cmp.Child("bar")
// Add redis components to each of the foo and bar sub-components.
redisFoo := redis.InstConn(cmpFoo, "127.0.0.1:6379")
redisBar := redis.InstConn(cmpBar, "127.0.0.1:6379")
// Parse will descend into the Component and all of its children,
// discovering all registered configuration parameters and filling them from
// the command-line.
mcfg.Parse(cmp)
// Now that configuration parameters have been initialized, run the Init
// hooks for all Components.
mrun.Init(cmp)
// At this point the redis components have been fully initialized and may be
// used. For this example we'll copy all keys from one to the other.
keys := redisFoo.Command("KEYS", "*")
for i := range keys {
val := redisFoo.Command("GET", keys[i])
redisBar.Command("SET", keys[i], val)
}
}
While the examples given here are fairly simplistic, the pattern itself is quite powerful. Codebases naturally accumulate small, domain-specific behaviors and optimizations over time, especially around the IO components of the program. Databases are used with specific options that an organization finds useful, logging is performed in particular places, metrics are counted around certain pieces of code, etc.
By programming with component structure in mind, we are able to keep these optimizations while also keeping the clarity and compartmentalization of the code intact. We can keep our code flexible and configurable, while also re-usable and testable. Also, the simplicity of the tools involved means they can be extended and retrofitted for nearly any situation or use-case.
Overall, this is a powerful pattern that I’ve found myself unable to do without once I began using it.
As a final note, you can find an example implementation of the packages described in this post here:
The packages are not stable and are likely to change frequently. You’ll also find that they have been extended quite a bit from the simple descriptions found here, based on what I’ve found useful as I’ve implemented programs using component structures. With these two points in mind, I would encourage you to look and take whatever functionality you find useful for yourself, and not use the packages directly. The core pieces are not different from what has been described in this post.
Published 2019-08-02
This post is part of a series.
Next: Component-Oriented Programming
This site can also be accessed via the gemini protocol: gemini://mediocregopher.com/