.%*. .-.
.%@@@+. .--=%@@@-
=@@@@@@- :--+@@@@@@@@@*
*@%@@@@@%: :--=#@@@@@@@@@@@@#@@+
@@::%@@@@@@-: :::-=%@@@@@@@@@@@@@@%#*- :@*
.@@ =@@@@@@@@@+-:::::::-=*@@@@@@@@@@@@@@@@@@@%##- @@:
#@# +%@@@@@@@@@@@@@@@@@@@@@@@@@@@@@%%#*: -@@
#@- *%@@@@@@@@@@@@@@@@@%%%#= %@=
@@: -=+++== .. @@:
@@ . -@@@ +@@
#@% =@@@@- +@@@@# *+ %@#
#@- -@@@@@@@. +@@@@@% .%@@@@= @@:
@@: +@@@@@@@@@ +@+ +@@@ %@@@@@@@@@ -@@
@@ *@%@* :@@@ *@+ -@@@ %@@@@@@@@@@@# @@@
#@% %@ @% %@@ *@* .@@@ =@@@*@@ :@@@@ @@:
%@:## *@+ :@@ :@@ @@@ %@@: @# .@@@ .@@
@@:. @@: .@@ @@ @@@ %@: @@ @@% @@%
@@ -@@. =@@ @@. @@@ %@. #@- @@# @@.
%@% +@@. @@. %@- @@@ #@ @@. :@@ -@@
%@: +@@+ .@% #@= @@@.@ *@@ +@+ @@*
@@: +@@%. .%% *@+ @@@ %@@ -@# @@
@@ :@@@@@@% :@@ @@% %@@ @# *@@
%@@ #@@@@* @@ @@% %@@. %@. @@:
@@: ===: @@. @@% %@@: =@%. .@@
@@. #@= @@% %@@%+%@#. @@%
@@ +@* @@# -@@@@@* .@@
%@@ :@@ @@# %@@#: =@@
@@: .@@ @@# : @@=
@@. @@. @@# :@@
@@ #@= @@% %@%
#@@ +@+ #@% .@@
@@: =@# +@% =@%
@@ :@% -@@ @@+
@@ .@@ -@: -@@
-@@ @% .: *@#
@@* # @@.
@@ =@@
.@@ @@*
.@@ .@@
*@@ =@#
@@* @@*
@@ -@@
.@@ +@*
.@@ @@-
-@@ =@@
%@% #@*
@@ @@:
@@ +@@
.@@ %@+
:@% @@.
:@% *@%
-@. %@=
%@ @@.
@@ *@%
@@ %@=
@% @@:
:@% +@@
:@* =+- #@+
:@: .%@@@. @@-
-@ =@@@@@# :@@
=@ *@#.=@@% #@%
*@ #@- -@@% %@-
@@ #@: :@@% @@:
@@ #% .@@% .#@@* -@@
@% #% .@@% +@@@@@- %@%
@# %@ :@@% .@@@@@@@@ %@:
@# %@ :@@% +@@% .@@@@ @@:
@# %@ :@@% #@@: :@@@ -@@
@# @@. .@@@ .@@% .@@@= %@%
@# @@. .@@@: %@@- @@@% %@:
@# @@ @@@@ %@@@ *@@@ @@:
@# .@@ @@@@@@@@@@= :@@@ @@
* @@@ :@@@@@@@@. :@@@ *@@
.@@@@@% -@@@@@. .@@@ @@=
@@@@@: .. @@@ @@.
-@%: @@@ @@.
@@@ @@
-@@ =@@
.@@ @@+
.@@:@@.
@@#@-
@@@.
+@-
-
mediocregopher's lil web corner
- Without using the word which starts with "W" and ends in "3".
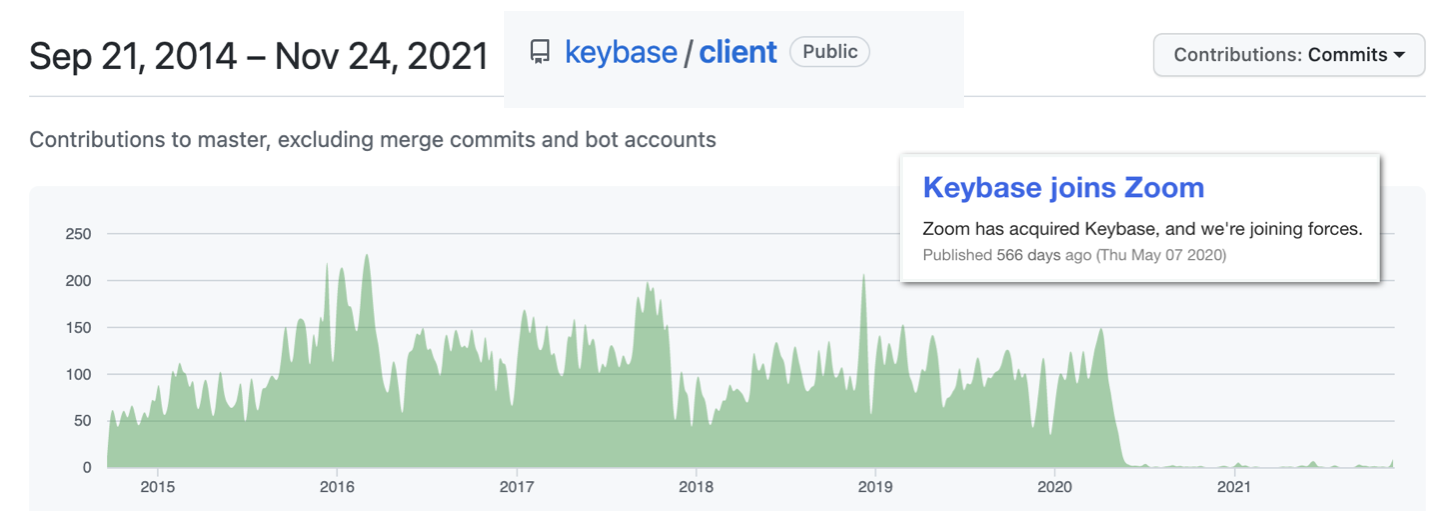
Today I saw an image which made feel deeply sad. This one:
In May of 2020 Keybase, one of my all-time favorite web services, was bought by Zoom, the international collaboration sensation. Almost precisely since that moment, Keybase has effectively been put on ice. The final post on the Keybase Blog is refreshingly up-front about this:
Initially, our single top priority is helping to make Zoom even more secure. There are no specific plans for the Keybase app yet. Ultimately Keybase's future is in Zoom's hands, and we'll see where that takes us. Of course, if anything changes about Keybase’s availability, our users will get plenty of notice.
To be fair, there are still a few devs still handling Github issues and committing code. The servers have not been shut down, user data is not lost. The source code, for both client and server, is still available. The lights are still on! Nevertheless, I've made every effort to move my data off of Keybase.
This hasn't been done lightly. I was a long-time Keybase user, frequent advocate, and even friend to some of the team. Keybase has a lot of cool features built on top of its rock-solid private storage, and I used them to build the foundation of my digital presence over many years. Clearly, I don't want to leave Keybase. It feels like saying goodbye to an old friend.
But I've seen this movie before, and I know how it ends. At least doing it now means I can find replacements for each of Keybase's features at my leisure, rather than being forced into doing so in a scramble just before the hammer falls.
The source code for Keybase is, right now, fully open source on their Github. Why couldn't someone spin up their own copy for themselves and their friends, give it a stupid name, and keep the party rolling?
The reason is that Keybase wasn't designed to be hosted by anyone except the Keybase team. There's no documentation on how to run the backend, and only a 9-page long string of Github projects to go on. Even if someone were to figure it out, the system is probably designed to be a globally scalable service, not a small clone being hosted for the benefit of a few. The design and expense of two such systems are vastly different, and not always compatible.
While the Keybase source code may be open, the infrastructure is closed.
Infrastructure refers to the computer hardware which hosts data and runs processes on behalf of a service's users, as opposed to users doing so themselves. Users generally have very small resources, think a phone or laptop, which are not always online. If you want to host 22 terabytes of family photos, you won't be doing so on your laptop.
You might instead upload them to Keybase, in which case Keybase's servers will hold onto them for you, and make them available to you whenever you want to view them. You are now a user of the Keybase service, which is hosted on the Keybase company's infrastructure.
This arrangement, dubbed a "cloud service", is exceedingly common in the tech industry, and its weakest point is the company part. Even if the code and the infrastructure are perfect, and users are completely hooked, and the service could change the world... if there's no money there's no company.
And yet, even if there is no money, the company must still posture as if there is going to be, in order to attract investors. These investors then pay for the infrastructure, in exchange for a cut of any future money.
This posturing excludes anyone who's not downstream of the company from participating in hosting the infrastructure, as they might then deserve some of the money too. The investors will likely make more by selling the whole company to a bigger fish than if they dilute their share of the profits. This is reflected in the design of the infrastructure itself. It's locked down to anyone not employed, directly or indirectly, by the company.
In the end the services we rely on rank profitability and exclusivity over usefulness and endurance, and the internet is worse off for it. We can do better.
Open infrastructure is the idea that anyone can help host the infrastructure of a service they care about, without any barriers to them doing so beyond their ability to manage the hardware.
The developers of an open infrastructure service don't have to actually manage the infrastructure themselves, a demanding and time-consuming task, so the service can be built by volunteers or a small company that isn't directly making money from the service. And because usefulness now ranks above profitability, the actual needs of the users of this service can be directly addressed.
None of these ideas around open infrastructure are new, though the wording might be, and there's already quite a bit of progress made in this direction. To get a feel for this progress it's worth perusing some of the existing projects and communities in this space. As we do so I'm going to break the open infrastructure space up into three notable, though frequently overlapping, parts: self-hosted, federated, and distributed.
Self-hosted services are those designed to be hosted by individuals or households for their own personal use. They may be hosted on a home-server, Raspberry Pi, or other similar device. One installation of a self-hosted service often never interacts with another, as the user's own infrastructure is enough to accomplish the service's goal.
Examples of self-hosting use-cases include:
A personal website or blog (like this one)
Media library platforms (Jellyfin, Ultrasonic)
Photo and video sync/storage (Piwigo)
Document archival and search (Paperless)
Entire "cloud" replacement suites (NextCloud)
Self-hosting is popular among enthusiasts, but is not popular outside that realm due to the requirement of managing your own infrastructure.
Federated services are designed to be hosted by a small to medium sized entity, and to serve many more users than are involved in the hosting. The entity may be a company servicing its employees, members of a community hosting services for their peers, or a paid service hosting for its customers. One installation of a federated service will often communicate with another by design, so that users of the one installation may interact with those on another.
Email is the classic example of a federated service. Each user has an account with someone running an email server, and they use those servers to exchange messages with users of other email servers. In the past it wasn't uncommon for an ISP to host a mail server for its customers, and to this day many companies still manage email servers for their employees.
The line between federated and self-hosted can sometimes be quite blury, as it's frequently possible for an individual to set up a federated service just for themselves.
Examples of federation use-cases, besides email, include:
Chat servers (IRC, Matrix)
Micro-blogs, aka Twitter replacements (Mastadon, MissKey)
Code hosting (Gitea)
Social link aggregators, aka Reddit replacements (Lemmy)
Video streaming platforms (PeerTube)
Where self-hosted services are hosted by-and-for individuals or very small groups, and federated services are hosted by small groups for larger groups, distributed services are hosted by both individuals and groups for everyone.
The key differentiator between a federated and a distributed service is that in a federated service the user interacts with a specific server, or set of servers, that they have a relationship with. In a distributed service the user has no relationship with those who run the infrastructure, and so users interact with whoever they can get ahold of.
Examples of distributed service use-cases include:
Data distribution (IPFS, BitTorrent magnet links)
Distributed transaction ledgers (Blockchains, love 'em or hate 'em!)
Onion routing (Tor)
There aren't many examples of truly distributed services that have stood the test of time, as the protocols and algorithms used to manage these global datasets are quite tricky to get right. It's possible that the recent advent of blockchains will change this, though blockchains usually assume some sort of direct compensation from users to "miners", a barrier not usually found in federated services.
I don't delineate these categories in order to direct you to one or the other, or to exhaustively list every ongoing project in this space. Rather, I hope this gives you a starting point if you're wondering what sorts of problems are able to be solved using open infrastructure, and how people are approaching them. Perhaps there's a problem you care about, and there's a way to solve it using an open infrastructure based solution.
The ideas presented here aren't some pie-in-the-sky, utopian fantasy; this is happening, and it's happening for good reasons. Some may argue that infrastructure can't survive without a profit model to pay for it, or that for-profit services are of higher quality and so free versions will never take off, or that if services are free to host then no one will make them. People said much the same about open source software.
The open source movement has shown that participation, not profitability, is the primary driver of successful software. Why should it not be the case for our service infrastructure?
Footnotes
I use a lot of words here whose definitions are by no means agreed upon. I've done my best to stick to my best understanding of word meanings, and to be consistent in them. If you disagree with my usage of a word, I'm sorry. It doesn't mean either of us is wrong, we just speak different.
There is an existing project, under the OpenStack project, called Open Infrastructure. It has to do with some kind of standardization around the infrastructure used for cloud services. Unfortunately, the word "infrastructure" has a much broader meaning than what they are using it for, and I don't think there's a better word for what I'm trying to describe.
Published 2022-03-13
This post is part of a series.
Previously: The Cryptic Filesystem
Next: Public Release of cryptic-net
This site can also be accessed via the gemini protocol: gemini://mediocregopher.com/